
@WeRateDogs Data Wrangling Analysis And Visualization
Udacity Scholarship |Advanced Data Analytics| Submission July 11,2022| Project II |Maximilien Kpizingui | Machine Learning & IoT Engineer


Welcome back to this blog post in advanced data analytics nanodegree scholarship sponsored by Udacity. The project II WeRateDogs, a twitter account which has 9.3 million followers across the world at the point this blog is published contains three datasets namely twitter-archive-enhanced.csv, image_predictions.tsv and tweet_json.txt which we have to programmatically download from three different sources. Two from website URLs and the last one requires the learner to sign up for twitter developer account to collect additional tweet through twitter API. The objective of this project is to challenge the learner to wrangle the three datasets and to combine all the three clean datasets into a twitter master archive by providing at least four insights and two visualizations. Without delay let's get into the data wrangling.
Table of Contents
- Loading the libraries
- Data gathering
- Reading twitter-archive-enhanced dataset into a dataframe
- Downloading image prediction dataframe using request
- Reading image prediction into a dataframe
- Query tweet_json dataset using twitter API
- Reading tweet_json into a dataframe
- Assessing data
- Objectives
- Methodology
- Visual assessment of twitter_archive_df
- Programmatic assessment of twitter_achive_df
- Visual assessment of image_predictions_df
- Programmatic assessment of image_predictions_df
- Visual assessment of tweet_status
- Programmatic assessment of tweet_status dataframe
- Project scope
- Quality issues
- Tidiness issues
- Cleaning data
- Making the copy of the dataframes
- Quality issue #8: Convert tweet_id column in image_predictions_clean from int to str
- Quality Issue #6: Inconsistent use of lowercase and uppercase and underscores in p1, p2,p3 columns
- Quality Issue #7: Removing duplicated values img_url of image_prediction_df
- Quality Issue #4: Incorrect values and incorrect type for timestamp
- Quality Issue #1: invalid and missing dog name in the column name
- Tidiness Issue #1 : Column source contain HTML tag and hyperlinks
- quality Issue #10: Removing RT @ in column text of twitter_archive_clean
- Quality Issue #5 : dropping columns in_reply_to_status_id, in_reply_to_user_id, retweeted_status_id,retweeted_status_user_id, retweeted_status_timestamp
- Tidiness Issue #2: Merging columns doggo, floofer,pupper, and puppo
- Tidiness Issue #4: There are two information in a single column text url link and text
- Quality Issue #2 and 3#: Invalid ratings. Value varies from 1776 to 0. data type must be converted from int to float. Invalid denominator, I expected a fixed base. data Strucutre must be converted from int to float.
- Tidiness Issue #5: Merging twitter_archive_clean and image_predictions_clean
- Quality Issue #9: Incorrect data type in column id in tweet_status_clean
- Tidiness isssue #6: Creating a dataframe with columns: id, favorite_count, retweet_count
- Tidiness isssue #7: Merge tweet_status_clean and twitter_achive_merged
- Storing the master data into csv file
- ANALYSING AND VISUALIZING THE DATA
- Reading the twitter_archive_master.csv into a dataframe
- Insight about the clean master dataset
- Visualizing the hidden pattern in the dataset
- Function to plot the average count of tweets
- Visualizing the distribution of average favorite count of tweet using based on the dog category
- Visualizing the distribution of average retweet count based on the dog category
- Visualizing Likes vs Retweets
- Visualizing the most used devices by WeRateDogs users
- Visualizing the most popular name of the dogs
- Visualizing 20 dogs breed P2 predicted by twitter user on WeRateDogs
- Visualizing 20 dogs breed P3 predicted by twitter user on WeRateDogs
- Visualizing the dog category with the highest score
- Visualizing the dog category with maximum favorite count
- Visualizing the dog category with minimun retweet count
- Visualizing Total Tweets made by WeRateDogs per month between 2015 to 2017
- Visualizing some of the dogs image prediction p1
1. Loading the required libraries
from timeit import default_timer as timer
from IPython.display import Image
from tweepy import OAuthHandler
import matplotlib.pyplot as plt
import seaborn as sns
import datetime as dt
import pandas as pd
import numpy as np
%matplotlib inline
import requests
import tweepy
import json
import re
2. Data Gathering
- Reading the twitter-archive-enhanced.csv
twitter_archive_df = pd.read_csv('twitter-archive-enhanced.csv')
- Use the Requests library to download the tweet image prediction (image_predictions.tsv)
# Use Requests library to programmatically download tsv file from a website
url = 'https://d17h27t6h515a5.cloudfront.net/topher/2017/August/599fd2ad_image-predictions/image-predictions.tsv'
response = requests.get(url)
# Save tsv to file
with open('image_predictions.tsv', mode='wb') as file:
file.write(response.content)
- Reading image_predictions.tsv in dataframe
image_predictions_df = pd.read_csv('image_predictions.tsv', sep='\t')
- Use the Tweepy library to query additional data via the Twitter API (tweet_json.txt) One of the Project requirements is to access the Twitter API to create the tweet_json.txt completing some missing/wrong values of the tweet-json file. I will use the tweepy package (a client code) to access the Twitter API.
- Authentication Details: load personal API keys (replaced with placeholders)
consumer_key = ''
consumer_secret = ''
access_token = ''
access_secret = ''
# variables for Twitter API connection
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_secret)
api = tweepy.API(auth, wait_on_rate_limit = True)
- Collecting tweet data using API
tweet_ids = twitter_archive_df.tweet_id.values
len(tweet_ids)
# Query Twitter's API for JSON data for each tweet ID in the Twitter archive
count = 0
fails_dict = {}
start = timer()
# Save each tweet's returned JSON as a new line in a .txt file
with open('tweet_json.txt', 'w') as outfile:
# This loop will likely take 20-30 minutes to run because of Twitter's rate limit
for tweet_id in tweet_ids:
count += 1
print(str(count) + ": " + str(tweet_id))
try:
tweet = api.get_status(tweet_id, tweet_mode='extended')
print("Success")
json.dump(tweet._json, outfile)
outfile.write('\n')
except Exception as e:
print("Fail")
fails_dict[tweet_id] = e
pass
end = timer()
print(end - start)
print(fails_dict)
- Reading tweet JSON content as pandas dataframe
tweet_status_df = pd.read_json('tweet_json.txt', lines = True,encoding='utf-8')
Assessing Data
Objectives
In this section, I detect and I document at least eight (8) quality issues and two (2) tidiness issue by using visual assessment and programmatic assessement
The issues could be defined into two types:
- Quality issues or dirty data: missing, duplicated, or incorrect data
- Tidiness issues: messy data or unstructural data.
Methodology
I use visual assessment on each dataframe to detect the issues and document it.
Visual assessment of twitter_archive_df
- Displaying the first five raw of the twitter_archive_df
twitter_archive_df.sample(3)
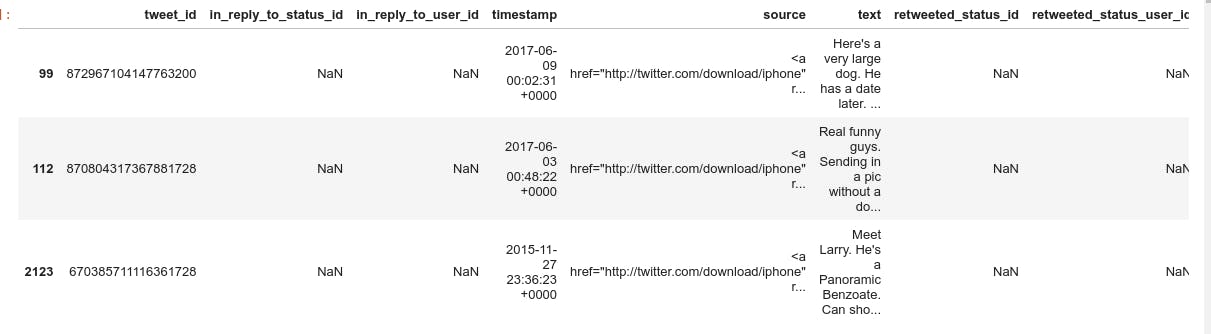
- We notice quality issue in column name cause it contains invalid name and missing name which are not accurate
- We notice tidiness issue in columns source HTML tags, URL, and content in a single column.
Programmatic assessment of twitter_archive_df
Through visual assessment we found invalid name in column name of the dataframe.
- Displaying 20 name of dogs
twitter_archive_df['name'][:20]
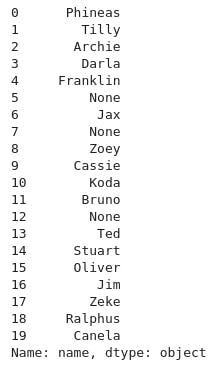
- Counting the occurence of the unique name of the dogs
twitter_archive_df['name'].value_counts()[:20]
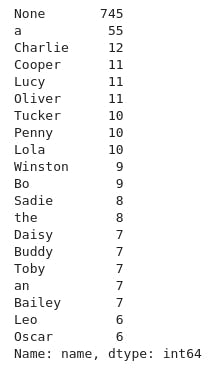
We notice 745 dogs in the dataframe have the name None and 55 dogs have the name a
Displaying the unique occurance of the denominator rating value
twitter_archive_df['rating_denominator'].value_counts()[:20]

We notice incorrect value in the rating_denominator column cause it must have a same denomination which is 10 leading to accuracy quality issue
Displaying the rating_numerator column
twitter_archive_df['rating_numerator']
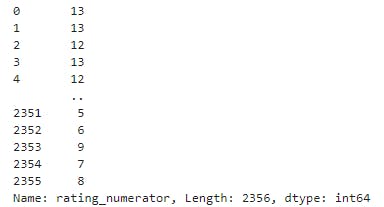
twitter_archive_df['rating_numerator'].value_counts()[:20]
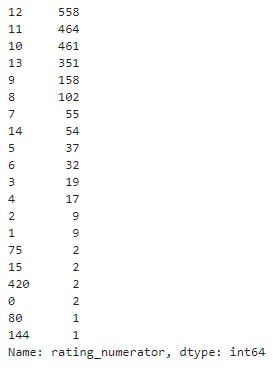
- The numerator values must be between 0 to 10 which is not the case leading to accuracy quality issue
Displaying descriptive information about the twitter_archive_df
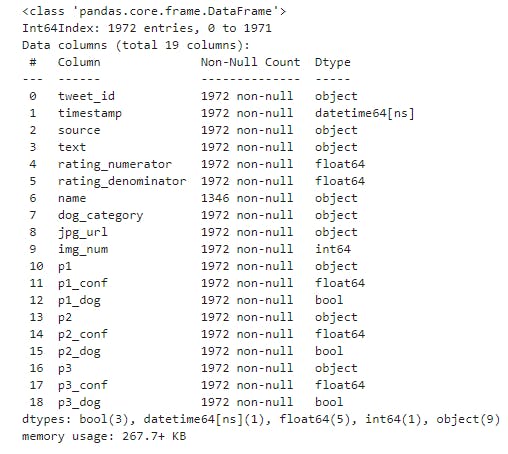
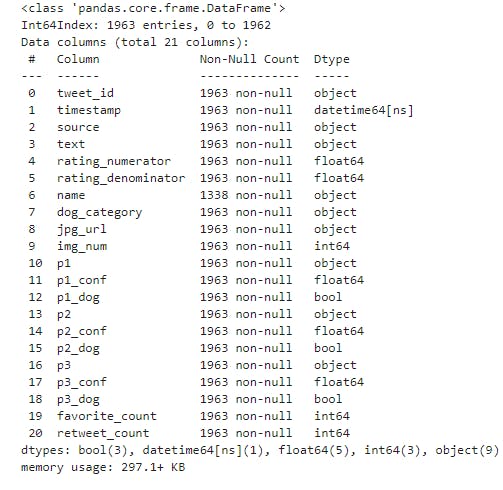
twitter_archive_df.info()
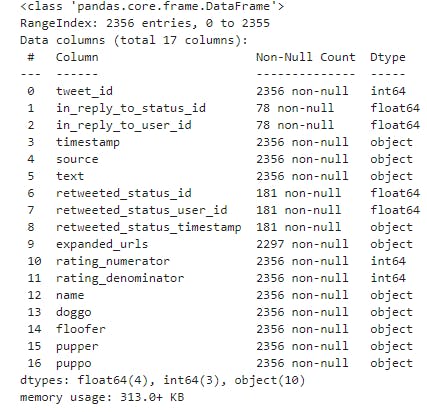
From the programmatic assessment we notice some quality issues
- timestamp column need to be converted to datetime
twitter_archive_df.pupper
twitter_archive_df.doggo
twitter_archive_df.floofer
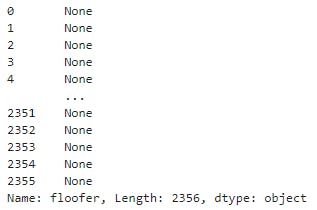
twitter_archive_df.puppo
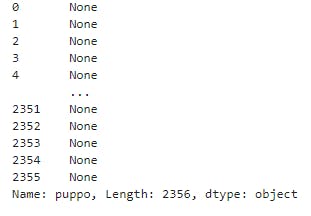
- From programmatic assessment we find a tidiness issue on columns doggo, floofer,pupper, and puppo they all have the same name and can be merge into 1 column
Checking for null values
twitter_archive_df.isnull().sum()
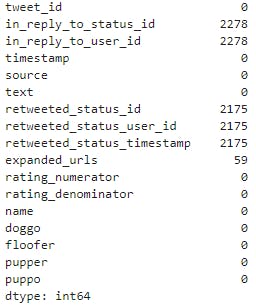
- in_reply_to_status_id, in_reply_to_user_id ,retweeted_status_id,retweeted_status_user_id, retweeted_status_timestamp columns have more null values which will bring bring about a quality issue we need to drop them
twitter_archive_df.text[:20]

- Checking the occurence of RT in the text column as it must be removed as specified in the project requirement
display(twitter_archive_df[twitter_archive_df['text'].str.contains('RT @')])
print('the number of RT in the text is:', sum(twitter_archive_df['text'].str.contains('RT @')))
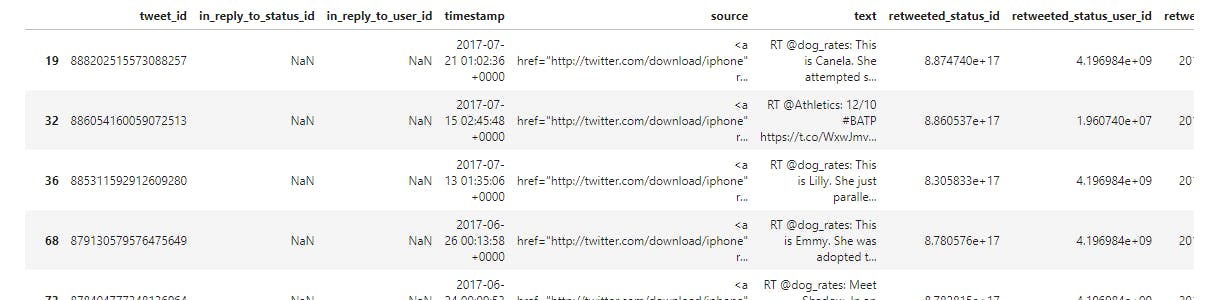
the number of RT in the text is: 181
Programmatically this is a quality issue cause text columns contains text and Url andv 181 retweets
Visual assessment of image_predictions_df
image_predictions_df.sample(4)

- From visual assessment we notice a quality issue on colums p1, p2 and p3 inconsistancy in the spelling of the name using upper case letter, lower case and underscore
Programmatic assessment of image_prediction dataframe
- Displaying the description of the image_predictions.tsv
image_predictions_df.info()
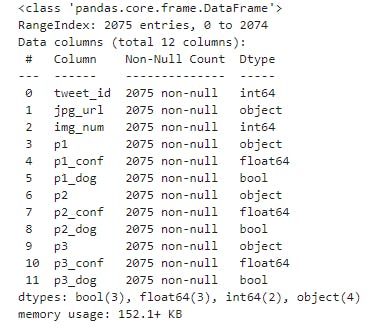
- From the descriptive information of the image_predictions dataframe, tweet_id need to be converted to a String data type cause it does not affect our analysis . So we raise a quality issue on the validity of the tweet_id data type
Checking for duplicated value
sum(image_predictions_df['tweet_id'].duplicated())

sum(image_predictions_df.jpg_url.duplicated())

- They are 66 duplicated jpg_url double entry bringing about a quality issue on the validity of the data
Visual assessment of tweet_status
tweet_status_df.sample(4)
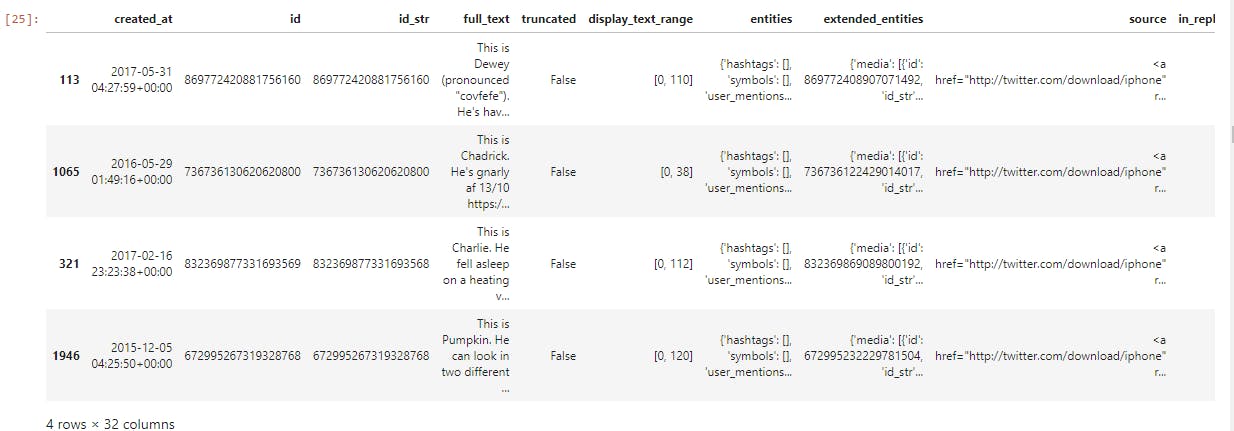
- We notice tidy issue in column in_reply_to_status_id, retweeted_status, quoted_status_id, quoted_status_id_str, quoted_status having NaN value
- We notice tidiness issue in columns source, entities, extended_entities having HTML tags, URL full_text contains RT @ which need to be remove per the project requirement
Programmatic assessment of tweet_status_df
tweet_status_df.isnull().sum()
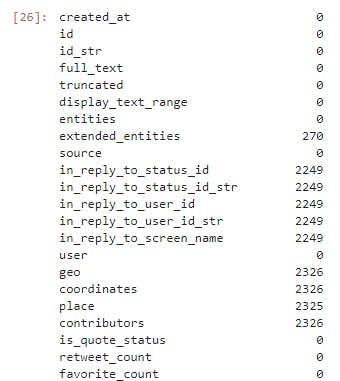
- we have quality issue on the validity of the data entry of the columns listed below having high number of NaN values therefore we need to drop
in_reply_to_status_id
in_reply_to_status_id_str
in_reply_to_user_id
in_reply_to_user_id_str
in_reply_to_screen_name
geo
coordinates
place
contributors
retweeted_status
quoted_status_id
quoted_status_id_str
quoted_status
Project scope
Based on the tidiness concept, twitter_archive_enhanced.csv,tweet_status_df, image_predictions.tsv should be merged using the tweet_id as a mapping key
Quality issues
invalid and missing dog name in the column name of twitter_achive_df
Invalid ratings in column rating_numerator of twitter_achive_df value varies from 1776 to 0 and data type need to be converted from int to float
Invalid denominator in column rating_denominator of twitter_achive_df. It should be a fixed base 10 and data type need to be converted from int to float.
Timestamp column in twitter_achive_df needs to be converted into datetime data type
in_reply_to_status_id, in_reply_to_user_id ,retweeted_status_id,retweeted_status_user_id, retweeted_status_timestamp have missing data
Spelling inconsistency of upper case letter in columns p1, p2 and p3 of image_predictions_df
jpg_url columns in image_predictions_df has 66 duplicated images and for the accurary of the data we need to drop them
tweet_id in image_predictions_df needs to be converted to string
column id in tweet_status_df need to be converted from in to string
column id need to be converted in tweet_id
Tidiness issues
- HTML tags, URL, and content in source column
- columns doggo, floofer,pupper, and puppo they all have the same name and can be merge into 1 column
- twitter_archive_df and image_predictions_df and tweet_status_df can be marged There is two information in a single column text, ampasand and //n
- 3 useful columns: id, favorite_count, retweet_count in tweet_status_df
- Retweet need to be removed in text column and in full_text columns
Cleaning Data
In this section, we clean all of the issues I listed out above while assessing the data.
Making copies of the original dataframes
twitter_archive_clean = twitter_archive_df.copy()
image_predictions_clean = image_predictions_df.copy()
tweet_status_clean = tweet_status_df.copy()
Quality Issue #8:
Convert tweet_id column in image_predictions_clean from int to str
Define:
Converting tweet_id column from int to str
Code
image_predictions_clean.tweet_id = image_predictions_clean.tweet_id.astype(str)
Test
type(image_predictions_clean.tweet_id[0])
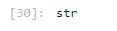
Quality Issue #6:
Inconsistent use of lowercase and uppercase and underscores in p1, p2,p3 columns
Define:
Replacing underscores ('_') with spaces and capitalize first letter.
Code
image_predictions_clean.p1 = image_predictions_clean.p1.str.replace('_', " ").str.capitalize()
image_predictions_clean.p2 = image_predictions_clean.p2.str.replace('_', " ").str.capitalize()
image_predictions_clean.p3 = image_predictions_clean.p3.str.replace('_', " ").str.capitalize()
Test
image_predictions_clean[['p1','p2','p3']].sample(6)
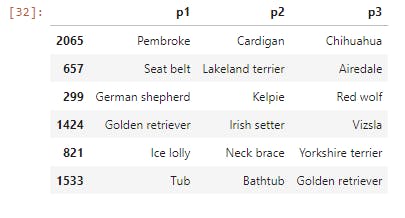
Quality Issue #7
Removing duplicated values img_url of image_prediction_df
Define:
Indexing all the duplicated value in jpg_url columns ;selecting the the non duplicating values and assigning the non duplicated jpg_url to image_predictions_clean
Code
indexing = image_predictions_df.jpg_url.duplicated()
indexing = np.logical_not(indexing)
image_predictions_clean= image_predictions_clean[indexing]
Test
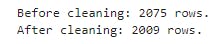
print("Before cleaning: {} rows.\nAfter cleaning: {} rows.".format(image_predictions_df.shape[0],image_predictions_clean.shape[0]))
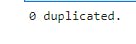
print("{} duplicated.".format(sum(image_predictions_clean.jpg_url.duplicated())))
Quality Issue #4:
Incorrect values and incorrect type for timestamp
Define:
Converting timestamp column from object to datetime series
Code
twitter_archive_clean['timestamp'] = twitter_archive_clean['timestamp'].astype('datetime64[ns]')
Test
twitter_archive_clean.timestamp[0]
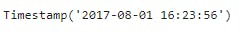
Quality Issue #1
invalid and missing dog name in the column name
Define:
Rename non-standard names to "None"
Code
invalid_names=list(twitter_archive_clean[twitter_archive_clean.name.
str.contains('^[a-z].*')].
name.value_counts().index) + ['None']
twitter_archive_clean.loc[twitter_archive_clean.name.apply(lambda x: x in invalid_names),'name']=None
Test
(twitter_archive_clean.name=='None').sum()

(twitter_archive_clean.name=='a').sum()

(twitter_archive_clean.name.apply(lambda x: x in invalid_names)).sum()
Quality Issue #10 :
twitter_data_archived contains retweets RT @ in column text
Define
As per project specification, we only want original dog ratings. We need to remove retweets text column starting with RT @. In order to fix this quality issue, we are going to create vectors to index all the non-retweet and we exclude the subset from the retweeted_status_id, retweeted_status_user_id, and retweeted_status_timestamp.
Code
indexing_retweeted_status_id =twitter_archive_clean.retweeted_status_id.isnull()
twitter_archive_clean = twitter_archive_clean[indexing_retweeted_status_id]
indexing_retweeted_status_user_id = twitter_archive_clean.retweeted_status_user_id.isnull()
twitter_archive_clean = twitter_archive_clean[indexing_retweeted_status_user_id]
indexing_retweeted_status_timestamp = twitter_archive_clean.retweeted_status_timestamp.isnull()
twitter_archive_clean = twitter_archive_clean[indexing_retweeted_status_timestamp ]
Test
print("Number of rows with true in retweeted_status_id:", sum(twitter_archive_clean.retweeted_status_id.isnull()))
print("Number of rows with true in retweeted_status_timestamp:", sum(twitter_archive_clean.retweeted_status_timestamp.isnull()))
print("Number of rows with true in retweeted_status_user_id:", sum(twitter_archive_clean.retweeted_status_user_id.isnull()))
print("Number of rows of twitter_archive_clean:",twitter_archive_clean.shape[0])
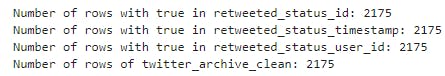
display(twitter_archive_clean[twitter_archive_df['text'].str.contains('RT @')])
print('the number of RT in the text is:', sum(twitter_archive_clean['text'].str.contains('RT @')))

twitter_archive_clean['text'].sample(45)

Tidiness Issue #1
Column source contain HTML tag and hyperlinks
Define:
Extracting the content between opening and closing tag using regular expressions. Extracting the link.
Replacing source variable in the dataset with just the source name
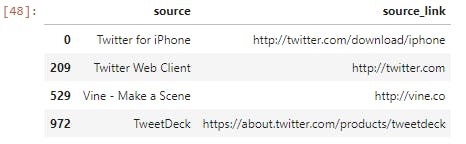
Creating additional table with source link that we could use as a lookup table.
Code
source_link = twitter_archive_clean.source.str.extract(r'<a href="(.+)" .+>', expand=False)
source = twitter_archive_clean.source.str.extract(r'>([A-z -]+)<', expand=False)
twitter_archive_clean.source = source
sources = pd.DataFrame({'source': source, 'source_link': source_link})
sources.drop_duplicates(inplace=True)
sources
Test
twitter_archive_clean.source.value_counts()

Quality issue
Dropping columns in_reply_to_status_id, in_reply_to_user_id, retweeted_status_id,retweeted_status_user_id, retweeted_status_timestamp and expanded_urls
Define:
Removing the columns in_reply_to_status_id, in_reply_to_user_id ,retweeted_status_id,retweeted_status_user_id, retweeted_status_timestamp
Code
columns_to_remove = ['in_reply_to_user_id', 'in_reply_to_status_id',
'retweeted_status_id', 'retweeted_status_user_id',
'retweeted_status_timestamp','expanded_urls']
twitter_archive_clean.drop(columns_to_remove, axis=1, inplace=True)
Test
twitter_archive_clean.columns

Tidiness Issue #2
Merging columns doggo, floofer,pupper, and puppo
Define
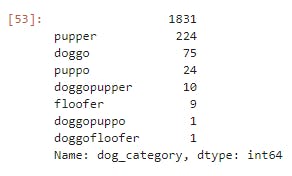
Columns doggo, floofer,pupper, and puppo have the same values therefore can be merged into one feature
Code
dog_cols = twitter_archive_clean[['doggo','floofer','pupper','puppo']]
dog_cols = dog_cols.replace('None', '')
dog_category = np.array(dog_cols['doggo']) + np.array(dog_cols['floofer']) + np.array(dog_cols['pupper']) + np.array(dog_cols['puppo'])
pd.DataFrame(dog_category, columns = ['dog_category']).dog_category.value_counts()
- Appending this new column called dog_category to the twtitter_archive_clean
twitter_archive_clean.reset_index(drop=True, inplace=True)
twitter_archive_clean = pd.concat([twitter_archive_clean, pd.DataFrame(dog_category, columns = ['dog_category'])], axis = 1)
- Dropping the individual columns after merging them
columns_to_remove = ['doggo','floofer','pupper','puppo']
twitter_archive_clean.drop(columns_to_remove, axis=1, inplace=True)
Test
twitter_archive_clean.dog_category.value_counts()

twitter_archive_clean.columns

Tidiness Issue #4
There are two information in a single column text.
Define
Remove the URL in the end of the text column, ampasamd and /n
Code
twitter_archive_clean['text'] = twitter_archive_clean.text.str.replace(r'[(https://.+),(\&)|(\n)]','',regex=True)
Test
twitter_archive_clean['text'].sample(45)

Quality Issue #2 and 3 :
Invalid ratings. Value varies from 1776 to 0. data type must be converted from int to float. Invalid denominator, I expected a fixed base. data Strucutre must be converted from int to float.
Define
- Convert rating_numerator and rating_denominator to float because @dog_rates uses float rating number.
- Remove the extreme values (1776, 420, etc.) of rating_numerator, and;
- Remove non expected value of denominator, anything different of 10.
Code
- Converting the rating_numerator and rating_denominator to float.
twitter_archive_clean.rating_numerator = twitter_archive_clean.rating_numerator.astype(float)
twitter_archive_clean.rating_denominator = twitter_archive_clean.rating_denominator.astype(float)
- From visual assessment of the rating_numerator done earlier on, we need to drop the numerator with invalid rating 1776, 420, 204.
invalid_ratings_1776_420_204= twitter_archive_clean[(twitter_archive_clean.rating_numerator==1776)|(twitter_archive_clean.rating_numerator==204)|(twitter_archive_clean.rating_numerator==420)].index
twitter_archive_clean.drop(invalid_ratings_1776_420_204, inplace=True)
- Removing tweet_id with 0/10
- Listing the tweet_id having 0 as numerator and removing these tweet_id from the dataframe
list(twitter_archive_clean.query('rating_numerator == 0').tweet_id)
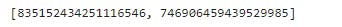
rm_list = list(twitter_archive_clean.query('rating_numerator == 0').tweet_id)
# Creating a vector to subset twitter_archive_clean and remove the tweet_id from the rm_list.
indexing = np.logical_not(twitter_archive_clean.tweet_id.isin(rm_list))
# Updating the twitter_archive_clean data frame.
twitter_archive_clean = twitter_archive_clean[indexing]
Test
twitter_archive_clean.query('rating_numerator == 0')

- Quering denominator other than 10
list(twitter_archive_clean.query('rating_denominator !=10').tweet_id)

- Remove those three tweet_id's
rm_list = list(twitter_archive_clean.query('rating_denominator !=10').tweet_id)
# Creating a vector to subset twitter_archive_clean and remove the tweet_id from the rm_list.
indexing = np.logical_not(twitter_archive_clean.tweet_id.isin(rm_list))
# Updating the twitter_archive_clean data frame.
twitter_archive_clean = twitter_archive_clean[indexing]
Test
twitter_archive_clean.query('rating_denominator < 10')

twitter_archive_clean.query('rating_denominator > 10')

twitter_archive_clean.rating_denominator.value_counts()

twitter_archive_clean.tweet_id =twitter_archive_clean.tweet_id.astype(str)
Merging twitter_archive_clean and image_predictions_clean as stating in the tidiness issue
twitter_archive_merged= pd.DataFrame()
twitter_archive_merged = twitter_archive_clean.copy()
twitter_archive_merged_df = twitter_archive_merged.merge(image_predictions_clean, on='tweet_id', how='inner')
print("Shape df_twitter_archive_clean: " + str(twitter_archive_merged.shape))
print("Shape image_predictions_clean: " + str(image_predictions_clean.shape))
print("Shape df_twitter_combined " + str(twitter_archive_merged_df.shape) + " after joining df_twitter_archive_cleaned, df_tweet_performance and df_image_predictions_cleaned.")

Test
twitter_archive_merged_df.info()
Quality Issue #11:
Incorrect data type in column id in tweet_status_clean
Define:
Convert id from int to str
Code
tweet_status_clean.id = tweet_status_clean.id.astype('str')
tweet_status_clean.rename(columns={'id':'tweet_id'}, inplace=True)
Test
type(tweet_status_clean.tweet_id[0])
Tidiness Issue #11:
Removing RT @ in full_text column
Define
Removing RT @ in full_text column as required in the project requirement
Code
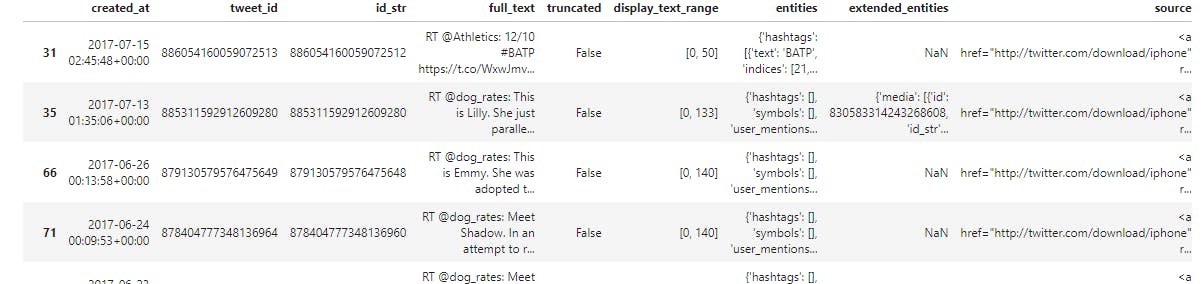
display(tweet_status_clean[tweet_status_clean['full_text'].str.contains('RT @')])
print('the number of RT in the text is:', sum(tweet_status_clean['full_text'].str.contains('RT @')))

- Removing the 160 retweet in full_text column
tweet_status_clean['full_text']= tweet_status_clean['full_text'].apply(lambda x: re.sub(r'\bRT @\b','',x).strip())
Test
sum(tweet_status_clean.full_text.str.contains('RT @'))

- All the rows have been removed
Tidiness isssue #6
Creating a dataframe with columns: id, favorite_count, retweet_count
Define Reassign the useful columns to the dataframe
Code
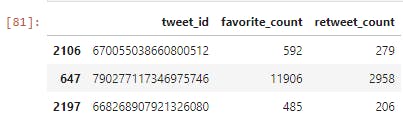
tweet_status_clean = tweet_status_clean[['tweet_id', 'favorite_count', 'retweet_count' ]]
Test
tweet_status_clean.sample(3)
Tidiness issue #7
Merge tweet_status_clean and twitter_achive_merged
Define
Merging tweet_status_clean and twitter_achive_merged
Code
twitter_archive_master = twitter_archive_merged_df.merge(tweet_status_clean, on='tweet_id', how='inner')
Test
twitter_archive_master.info()
Storing Data
Saving the clean merged dataframe into "twitter_archive_master.csv".
twitter_archive_master.to_csv('twitter_archive_master.csv', index=False)
Analyzing and Visualizing Data
In this section, we analyze the twitter archiv master dataset and visualizing data
-Reading and assessing the twitter_archive_master.csv into a dataframe
master_df =pd.read_csv("twitter_archive_master.csv")
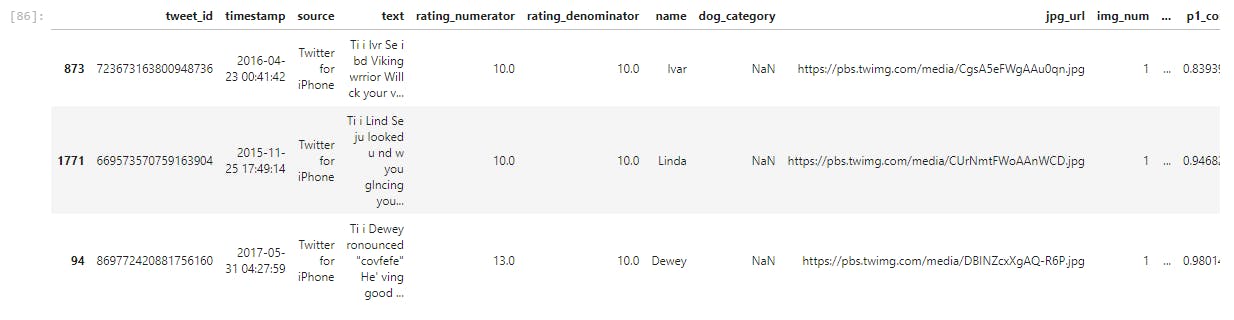
master_df.sample(3)
Insights: In this section, we are interesting to find the hidden pattern in the clean twitter archive master dataset.
. Visualizing the distribution of dog category based on the favorite tweet count by their users on twitter
. Visualizing the distribution of dog category based on the retweet count by their users on twitter
. Visualizing the most used devices by WeRateDogs users
. Visualizing the most common name of dog
. Line plot of like and retweet by twitter users on WeRateDogs account
.Visualizing 20 dogs breed P2 predicted by twitter user on WeRateDogs
. Visualizing 20 dogs breed P3 predicted by twitter user on WeRateDogs
. Visualizing the dog category with the highest rating score
. Visualizing the dog category with maximum favorite count
. Visualizing the dog category with minimum retweet count
. Visualizing Total Tweets made by WeRateDogs per month
. Visualizing some of the dog names in image prediction p1
Visualization
Define a function to plot the average count of tweets
def distributionPlot(feature,ylabel,title):
stage_favorite_counts = master_df[['dog_category',feature]]
stage_favorite_counts_agg = stage_favorite_counts.groupby('dog_category', as_index=False).mean()
print(stage_favorite_counts_agg )
f, ax = plt.subplots(1, 1, figsize=(12, 4));
sns.barplot(data=stage_favorite_counts_agg,x='dog_category',y=feature,color='green', ax=ax);
ax.set_ylabel(ylabel);
ax.set_xlabel("Dog category");
ax.set_title(title)
Plotting the distribution of average favorite count of tweet using based on the dog category
distributionPlot('favorite_count','average favorite count',"Distribution of average favorite count of tweet using based on the dog category¶")
plt.savefig('av_favcounte.png')
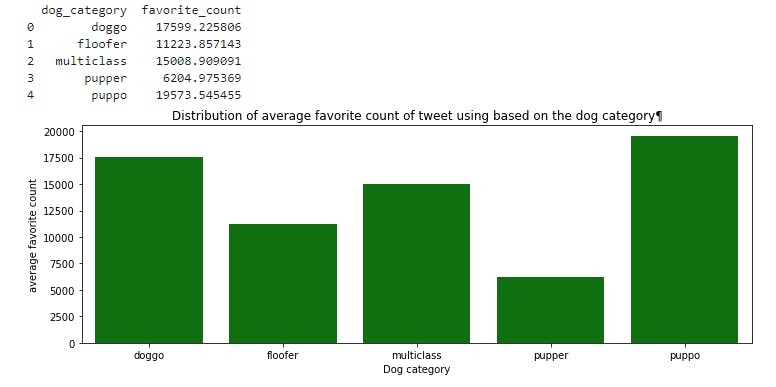
Among the dog category:
- doggo has 17599.225806 tweet favorite counts the most
- followed by floofer with 11223.857143 tweet favorite counts
- multiclass has 15008.909091 tweet favorite counts
- pupper has 6204.975369 tweet favorite counts
- puppo has 19573.545455 tweet favorite counts the least
Plotting the distribution of average retweet count based on the dog category
distributionPlot('retweet_count','average retweet count',' Distribution of average retweet count based on the dog category')
plt.savefig('av_retweet_count.png')
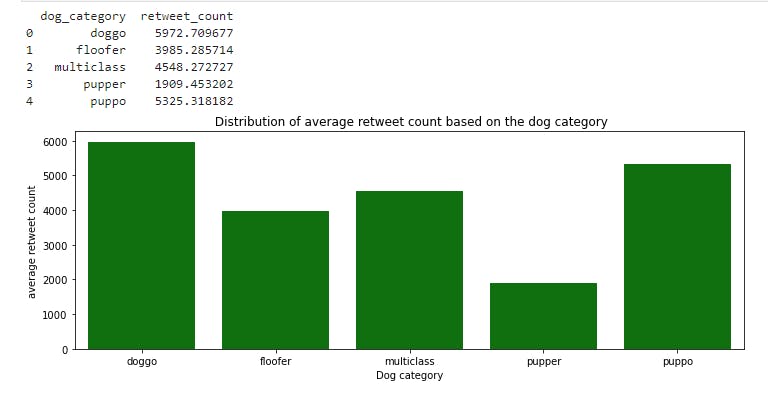
Among the dog category:
- doggo has 5972.709677 average retweet counts the most
- followed by puppo with 5325.318182 average retweet counts
- multiclass has 4548.272727 average retweet countss
- floofer has 1909.453202 average retweet counts
- pupper has 5325.318182 average retweet counts the least
Plotting likes vs retweets
likes = pd.Series(data=master_df['favorite_count'].values, index=master_df['timestamp'])
retweets = pd.Series(data=master_df['retweet_count'].values, index=master_df['timestamp'])
likes.plot(figsize=(16,4), label='Favorites', color='orange', legend=True)
retweets.plot(figsize=(16,4), label='Retweets', color='maroon', legend=True);
plt.title('No. of Favorites and Retweets Over Time')
plt.show()
plt.savefig('retvs.png')
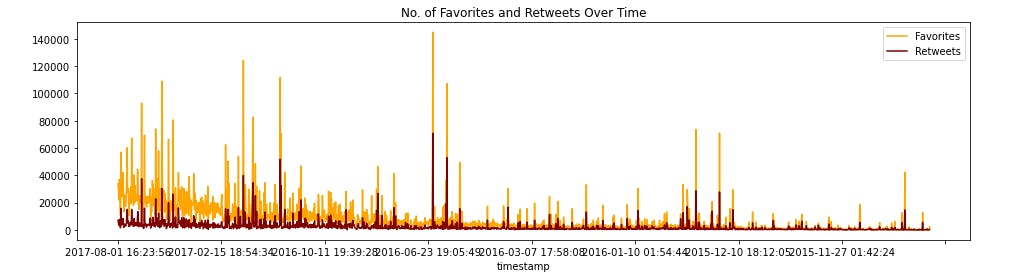
From the plot of likes vs retwets we notice that WeRateDogs twitter account started in December,11,2015 with zero likes and retweets. In June,23,2016 over 65k users retweeted post of the account and 140k people like the post as their favorites. In February,16, 2017, the account got more popularity over 100k people like the post on the account as their favorites and 25k people retweeted the posts about WeRateDogs.In August 1,2017 few people retweets about their dogs and only 58k people like the post of dogs as their favorites.
Visualizing the most used devices by WeRateDogs users
print(twitter_archive_clean.source.value_counts())
twitter_archive_clean.source.value_counts().plot(kind='bar', figsize=(11,5), title='Most used Twitter source').set_xlabel("Number of Tweets")
plt.savefig('twitter_source')
plt.savefig('twitter_source.png')
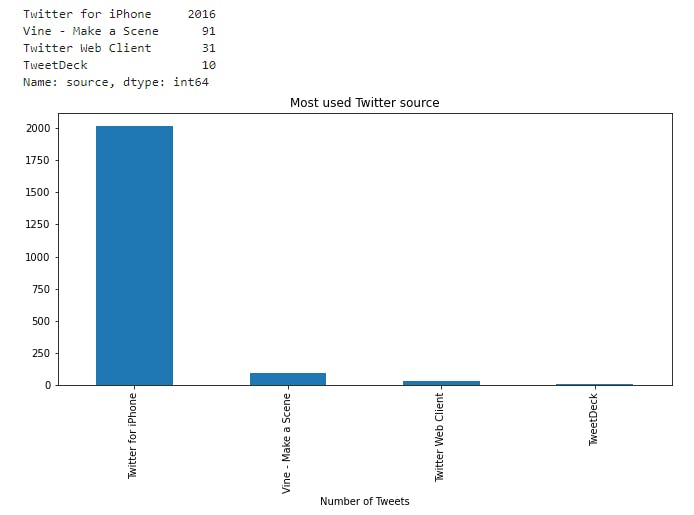
- From the bar plot above, most of the WeRateDogs users used Twitter for iPhone
From the bar plot above, most of the WeRateDogs users used Twitter for iPhone
Displaying the most common name among the dogs
master_df['name'].value_counts()[1:13]

Visualizing the most popular name of the dogs
sorted_order = master_df['name'].value_counts()[1:13].head(13).index
display(sorted_order)
plt.figure(figsize = (10,4))
values = np.count_nonzero(master_df['name'])
fclrs = ['grey' if (x > min(sorted_order)) else 'red' for x in sorted_order]
sns.countplot(data = master_df, x = 'name', order = sorted_order, orient = 'h')
plt.xlabel('Name', fontsize =16)
plt.ylabel('Count', fontsize =16);
plt.title('Most popular name of the dogs ')
plt.savefig('popular_dog_name.png')
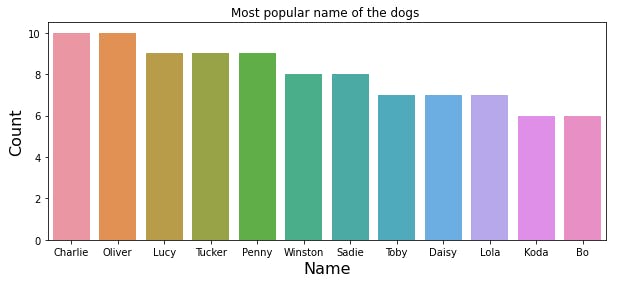
- From the above plot the most common name among the dogs are Charlie, Oliver, Lucy, Tucker, Penny, Winston, Sadie,Toby, Daisy, Lola, Koda and Bo
Visualizing 20 dogs breed P2 predicted by twitter user on WeRateDogs
breeds= master_df.p2.value_counts().head(20)
display(breeds)
plt.barh(breeds.index , breeds,color='red')
plt.xlabel('Count')
plt.ylabel('Dog Breed')
plt.title('Top 20 Dog Breeds prediction p2 on tweet')
plt.gca().invert_yaxis()
plt.show()
plt.savefig('20p2_dog_pred.png')
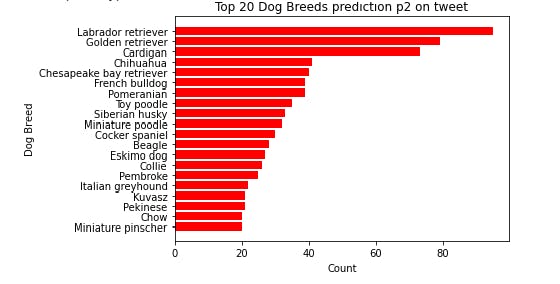
- From the above plot, the most predicted dog image by twitter users on WeRateDogs is Labrador retriever
Visualizing 20 dogs breed P3 predicted by twitter user on WeRateDogs
breeds= master_df.p3.value_counts().head(20)
display(breeds)
plt.barh(breeds.index , breeds,color='purple')
plt.xlabel('Count')
plt.ylabel('Dog Breed')
plt.title('Top 20 Dog Breeds predction on tweet')
plt.gca().invert_yaxis()
plt.show()
plt.savefig('20d0gs_p3.png')
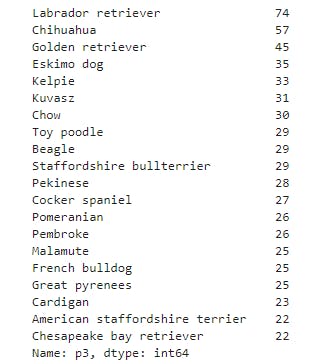
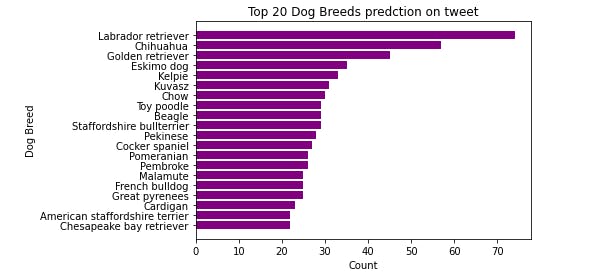
- From the above plot, the most predicted dog image by twitter users on WeRateDogs is Labrador retriver
Visualizing the dog category with the highest score
- Creating a new column called rating in master_df
master_df['rating'] = master_df['rating_numerator']/master_df['rating_denominator']
dog_rating=master_df.groupby('dog_category')['rating'].max()
print(dog_rating)
dog_rating.plot.bar(figsize=(10,5))
plt.ylim(top=10)
plt.title("Dog category with the highest rating score")
plt.xlabel("Dog category")
plt.legend([" Rating"])
plt.savefig('rating.png')
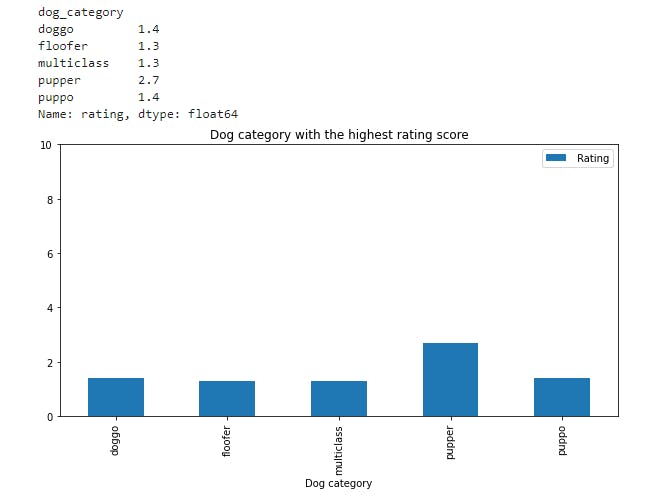
- From the plot above, pupper is the dog with the high rating score
Visualizing the dog category with maximun favorite count
dog_favorite_count=master_df.groupby('dog_category')['favorite_count'].max()
display(dog_favorite_count)
dog_favorite_count.plot.bar(figsize=(10,5))
plt.title("Dog category favorite count")
plt.xlabel("Dog category")
plt.legend(["favorite_count"])
plt.savefig('favorite.png')
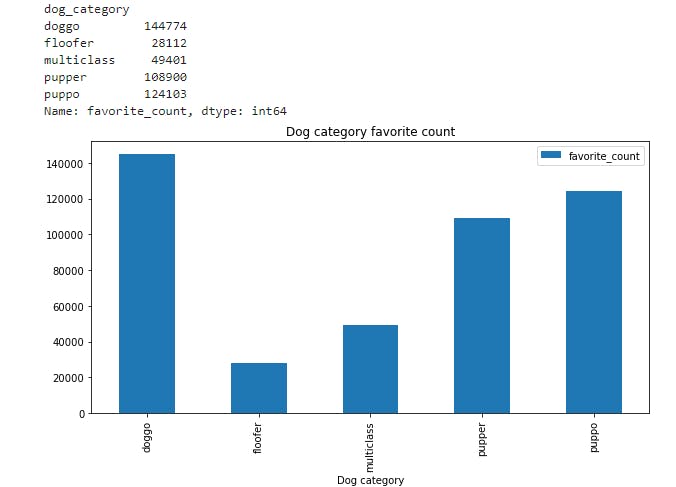
- From the above plot doggo is the dog with maximum twitter favorite count
Visualizing the dog category with minimun retweet count
dog_retweet_count=master_df.groupby('dog_category')['retweet_count'].min()
display(dog_retweet_count)
dog_retweet_count.plot.bar(figsize=(10,5))
plt.title("Dog category with minimun retweet count")
plt.xlabel("Dog category")
plt.legend(["favorite_count"])
plt.savefig('retweet.png')
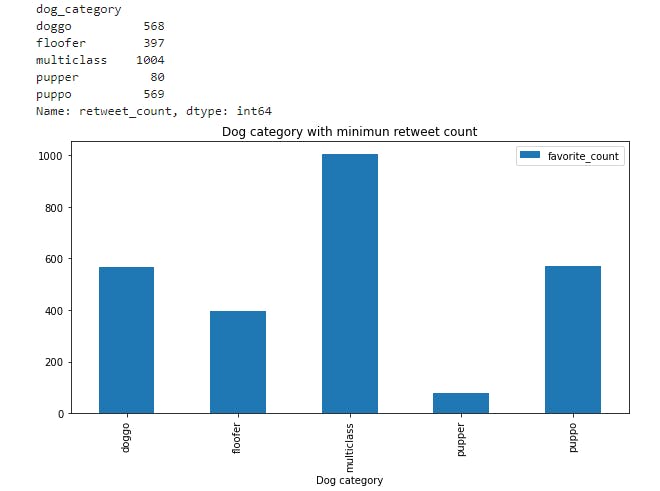
- From the above plot pupper has the least retweet count
Visualizing Total Tweets made by WeRateDogs per month between 2015 to 2017
twitter_archive_master['year_month_date'] = twitter_archive_master['timestamp'].dt.year.astype(str) + '-' + \
twitter_archive_master['timestamp'].dt.month.astype(str).str.pad(2, fillchar='0')
twitter_archive_master['is_tweet'] = np.where(twitter_archive_master.tweet_id.notnull(), 1, 0)
twitter_archive_monthly_tweets = twitter_archive_master.groupby('year_month_date').is_tweet.sum().reset_index()
plt.xticks(rotation=45)
ax = sns.lineplot(x='year_month_date', y='is_tweet', data=twitter_archive_monthly_tweets)
ax.set_title('Total Tweets made by WeRateDogs per month between 2015 to 2017')
ax.set_xlabel('Date')
ax.set_ylabel('Number of Tweets')
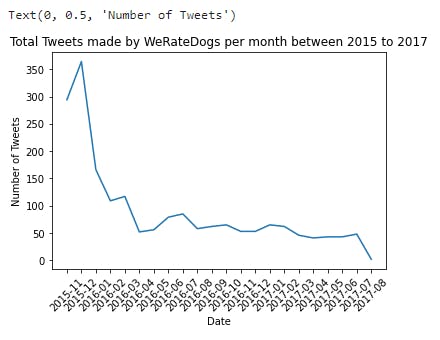
- From the plot above, we notice in November,2015, 350 people tweeted on WeRateDogs. However, the number gradually decreased in August 2017, the plot revealed that the number of tweets had dropped to 0 tweet.
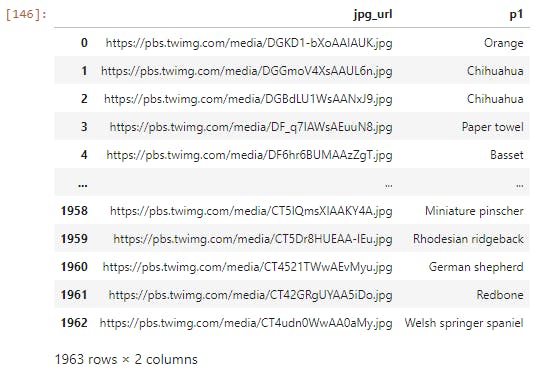
Visualizing some of the dogs image prediction p1
twitter_archive_master[['jpg_url','p1']]
Visualizing Miniature_pinscher
Image("https://pbs.twimg.com/media/CT5IQmsXIAAKY4A.jpg")

- Programmatically download Miniature_pinscher image from the url
response = requests.get("https://pbs.twimg.com/media/CT5IQmsXIAAKY4A.jpg")
file = open("Miniature_pinscher.png", "wb")
file.write(response.content)
file.close()
Visualizing Rhodesian ridgeback
Image('https://pbs.twimg.com/media/CT5Dr8HUEAA-lEu.jpg')

- Programmatically download Rhodesian ridgeback image from the url
response = requests.get("https://pbs.twimg.com/media/CT5Dr8HUEAA-lEu.jpg")
file = open("Rhodesian ridgeback.png", "wb")
file.write(response.content)
file.close()
Visualizing German Sheperd
Image('https://pbs.twimg.com/media/CT4521TWwAEvMyu.jpg')

- Programmatically download german_sheperd image from the url
response = requests.get("https://pbs.twimg.com/media/CT4521TWwAEvMyu.jpg")
file = open("german_sheperd.png", "wb")
file.write(response.content)
file.close()
Conclusion
We have reached the end of this data wrangling and visualization journey.
Through our analysis , we found out that:
Among the dog category we found out that:
tweet favorite counts
- doggo has 17599.225806 the most
- followed by floofer with 11223.857143
- multiclass has 15008.909091
- pupper has 6204.975369
- puppo has 19573.545455
retweet count
- doggo has 5972.709677 the most
- followed by puppo with 5325.318182
- multiclass has 4548.272727
- floofer has 1909.453202
- pupper has 5325.318182
Most devices used by WeRaDogs users
- Twitter for iPhone: 2016
- Vine - Make a Scene: 91
- Twitter Web Client: 31
- TweetDeck : 10
** Dog category with the highest rating score
- pupper 2.7
- doggo 1.4
- puppo 1.4
- floofer 1.3
- multiclass 1.3
dog category with maximun favorite count
- doggo 144774
- puppo 124103
- pupper 108900
- multiclass 49401
- floofer 28112
Finaly, People preferred to favorite a dog over a retweet and both actions had decreased over time from 2015 to 2017.
The github repository to download the datasets, the wrangling report and the jupyter notebook can be found here.
If you want to contribute or you find any errors in this article please do leave me a comment.
You can reach me out on any of the matrix decentralized servers. My element messenger ID is @maximilien:matrix.org
If you are in one of the mastodon decentralized servers, here is my ID @maximilien@qoto.org
If you are on linkedIn, you can reach me here
If you want to contact me via email for freelance maximilien@tutanota.de
If you want to hire me to work on machine learning, data science,IoT and AI related project, please reach out to me here
Warm regards,
Maximilien.