
Revolutionizing Healthcare Conversations: Building a Medical Chatbot Using LlamaIndex and DeepLake On Custom Dataset
Enhancing Patient Care with AI-driven Conversations


Introduction
In today's rapidly evolving society, telemedicine is redefining the contours of patient care. As healthcare providers migrate to virtual consultations, patients seek clarity and relevance in their digital interactions. However, building a chatbot that transcends the typical to offer truly intuitive telemedical interactions is not an easy feat for developers. In this blog, we leverage the transformative potential of LlamaIndex and DeepLake for an unparalleled precision and responsiveness chatbot.
Contents
LlamaIndex
Deep Lake
Power and Limitations of LLMs
Application Integration: Data Indexing
Application Integration: Query Stage
Code Implementation
LlamaIndex
LlamaIndex is a simple, flexible data framework for connecting custom data sources to large language models. It offers a suite of essential tools designed to streamline the process of leveraging private or domain-specific data within LLM-powered applications:
Data Connectors: These versatile components are responsible for ingesting data from their native sources and formats. LlamaIndex supports a wide range of data sources, including APIs, PDF documents, SQL databases, and more.
Data Indexes: LlamaIndex employs data indexing to structure information into intermediate representations that are not only easy for LLMs to understand but also highly performant. These structured data representations serve as a bridge between raw data and natural language understanding.
Engines: LlamaIndex features different types of engines that provide natural language access to your structured data:
Query Engines: These engines serve as robust retrieval interfaces, enabling knowledge-augmented output. They are ideal for information retrieval tasks and quick access to relevant data.
Chat Engines: For applications requiring interactive and conversational experiences, LlamaIndex provides chat engines that support multi-message, "back and forth" interactions with the data, making it suitable for dynamic conversational interfaces.
Data Agents: LlamaIndex empowers knowledge workers by integrating Large Language Models with various tools, ranging from simple helper functions to API integrations and more. These agents can assist with data-related tasks and augment human decision-making.
Application Integrations: LlamaIndex ensures seamless integration with the broader ecosystem of applications following two key stages namely:
Data indexing Stage
Query stage
Deep Lake
Deep Lake is a database optimized for deep learning and AI applications, powered by a specialized storage format. Deep Lake can be used for:
Storing data and vectors while building applications
Managing datasets while training deep learning models
Deep Lake simplifies the deployment of enterprise-grade LLM-based products by offering storage for all data types (embeddings, audio, text, videos, images, pdfs, annotations, etc.), querying and vector search, data streaming while training models at scale, data versioning and lineage, and integrations with popular tools such as LangChain, LlamaIndex, Weights & Biases, and many more.
Deep Lake works with data of any size, it is serverless, and it enables you to store all of your data in your cloud. Deep Lake is used by Intel, Airbus, Matterport, ZERO Systems, Red Cross, Yale, & Oxford.[read more about deeplake]
Power and Limitations of Large Language Models
Large Language Models (LLMs) are trained on vast text volumes to learn the word distribution in a language, allowing them to generate meaningful content without direct data memorization. They can recall widespread information like historical events. However, their knowledge is limited to their training data, leading them to potentially "hallucinate" or fabricate details about events or facts after their last training update. This is a concern for applications needing high reliability.

A solution to this is using retrievers alongside LLMs. Retrievers fetch accurate information from trusted databases which the LLM uses without adding fictional details.
Application Integration: Data indexing stage

During this stage, a knowledge base is prepared. This involves organizing and structuring the custom data to make it easily retrievable and accessible. The knowledge base acts as a source of information for the LLM.
Data Source: This is the external data and can be in any form (CSV, pdf, word, excel, web-based) on the data source, relevant Data loaders are used to process the data.
Documents / Nodes: A Documents/Node here represents a fundamental unit of data in LlamaIndex, containing a chunk of a source Document with comprehensive metadata and inter-node relationships for precise retrieval actions.
Data Indexes (VectorStoreIndex): LlamaIndex streamlines data indexing by converting raw documents into intermediary representations, generating vector embeddings, and deducing metadata, with the VectorStoreIndex being a prevalent index format facilitating efficient data retrieval.
Application Integration: Query stage
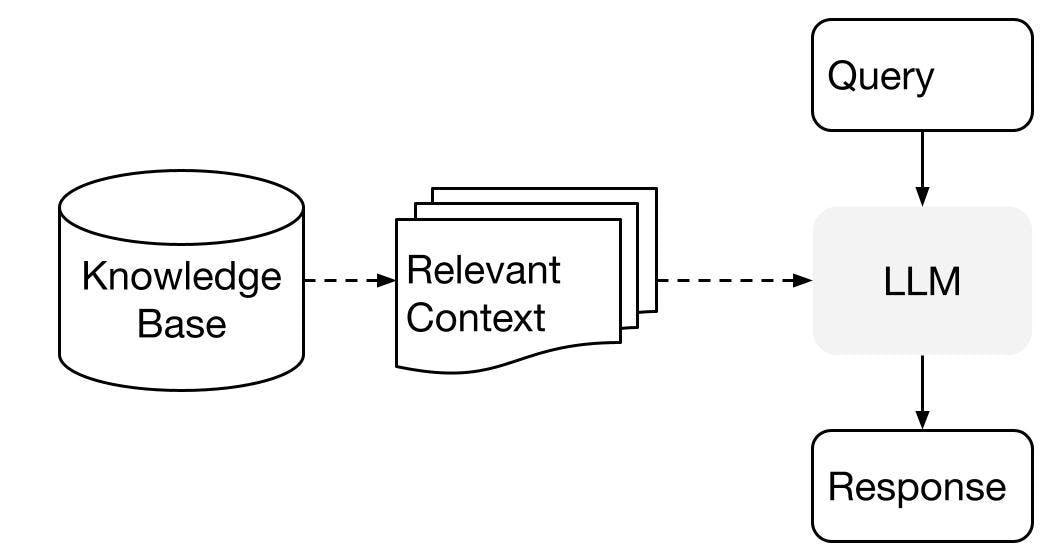
In this stage, the system retrieves relevant context from the knowledge base based on a query. This retrieved-context is then used to augment the LLM's understanding and generation capabilities. The LLM can utilize this additional information to formulate more informed and accurate responses to user queries.
Code implementation
Installing DeepLake and llama_index
pip install deeplake llama_indexImporting the required dependencies
from llama_index import GPTVectorStoreIndex, SimpleDirectoryReader, Document from llama_index.vector_stores import DeepLakeVectorStore import textwrap import getpass import os
Defining the openai API key and active loop token using getpass to hide the credentials from public view
os.environ["OPENAI_API_KEY"] = getpass.getpass(prompt='Enter your OPENAI_API_KEY: ')
os.environ["ACTIVELOOP_TOKEN"] = getpass.getpass(prompt='Enter your ACTIVELOOP_TOKEN: ')
When you run this, you'll be prompted to enter the values for each key. The values won't be displayed as you type, which helps maintain security, especially when working in shared or public environments.
Loading the dataset
The datasets used in this code are: symptom precautions in "xls format" and symptom descriptions in "doc format" of various sicknesses as shown below
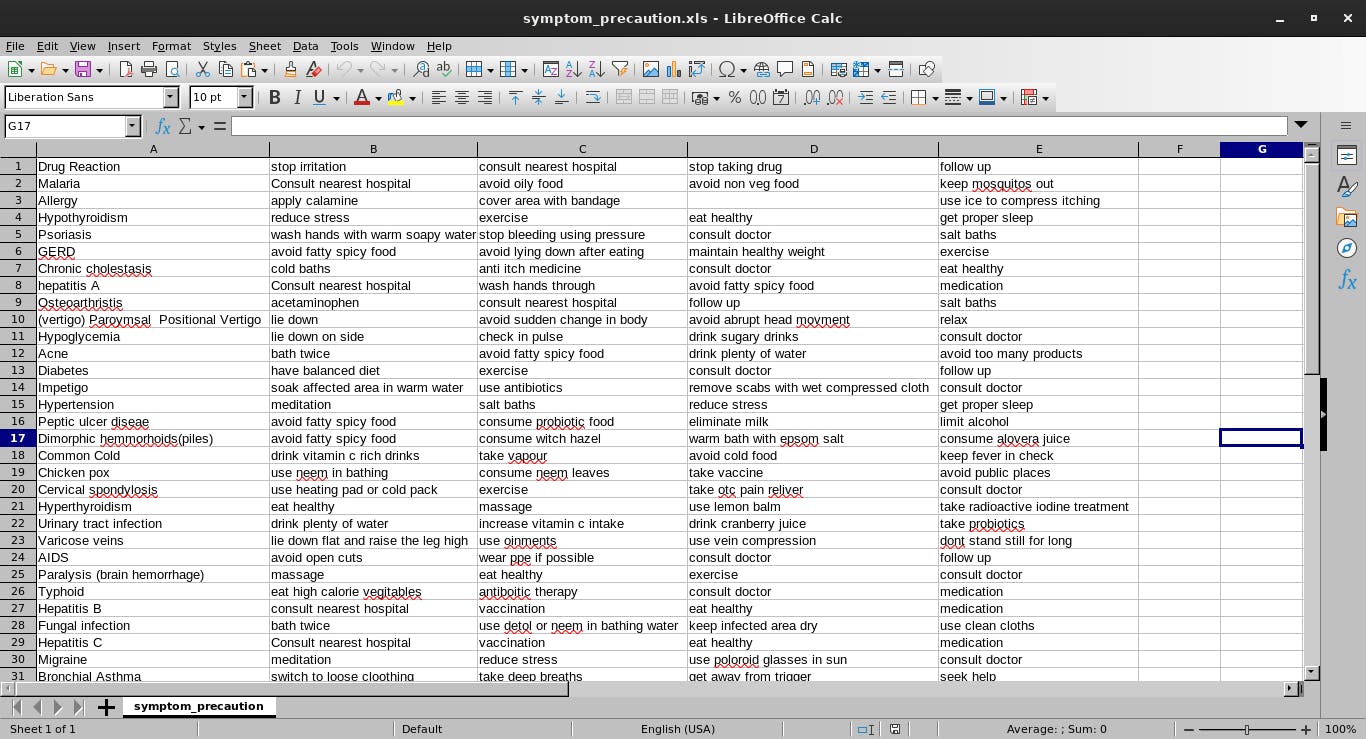
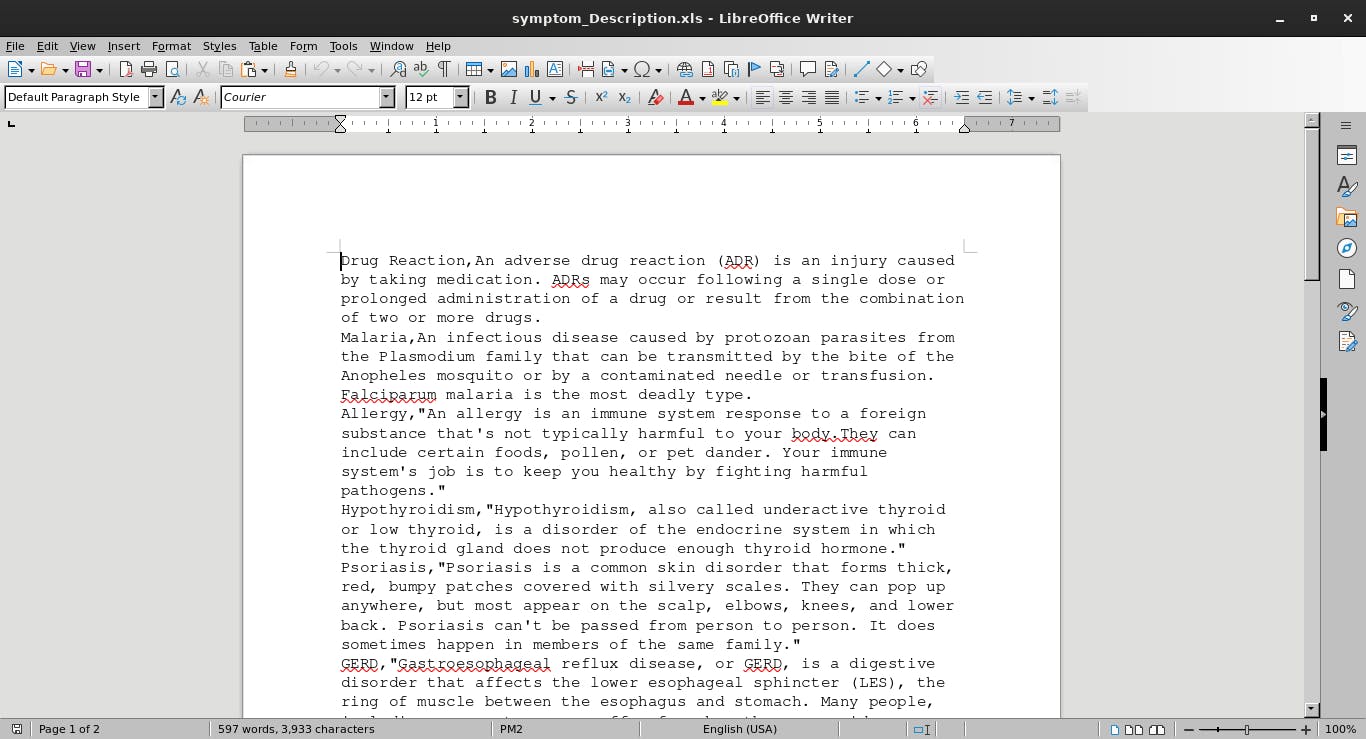
Create a folder in the project directory called data containing the two datasets. Link to download the dataset here
Loading the dataset
path_document =<'path of the data folder'>
documents = SimpleDirectoryReader(path_document).load_data()
Vectorizing and indexing the dataset
dataset_path = "hub://activeloop_username/text_embedding" vector_store = DeepLakeVectorStore(dataset_path=dataset_path, overwrite=True) storage_context = StorageContext.from_defaults(vector_store=vector_store) index = GPTVectorStoreIndex.from_documents(documents, storage_context=storage_context)This code stores and indexes the documents in a vectorized form. It starts by defining where and how the vectors will be stored (DeepLakeVectorStore), sets up a storage context (StorageContext), and then creates an index (GPTVectorStoreIndex) for the documents using that storage context.
You should see an output like this stating that the dataset has been created successfully in DeepLake
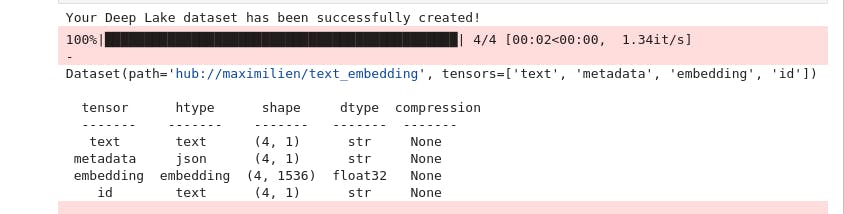
Alternatively, if you don't want to store the embedding in DeepLake, use GPTDeepLakeIndex to store it locally
vector_store = DeepLakeVectorStore(overwrite=True)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = GPTVectorStoreIndex.from_documents(documents, storage_context=storage_context)
The output of this code creates a folder llama_index containing the tensors
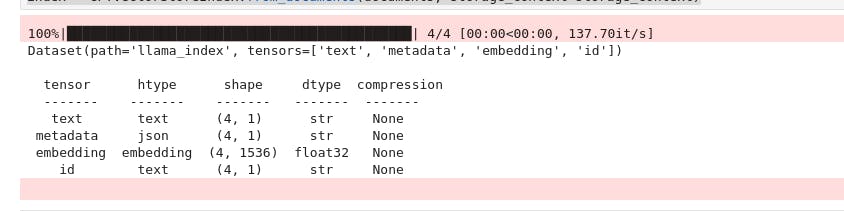
Initializing the query engine
The query engine is a generic interface that allows you to ask questions about your data.
query_engine =index.as_query_engine()
Query the bot about symptoms of illness, precautions to take, cure etc.
response = query_engine.query("What are the symptoms of malaria?")Displaying the output
print(textwrap.fill(str(response), 50))
- Output

Let's play around it
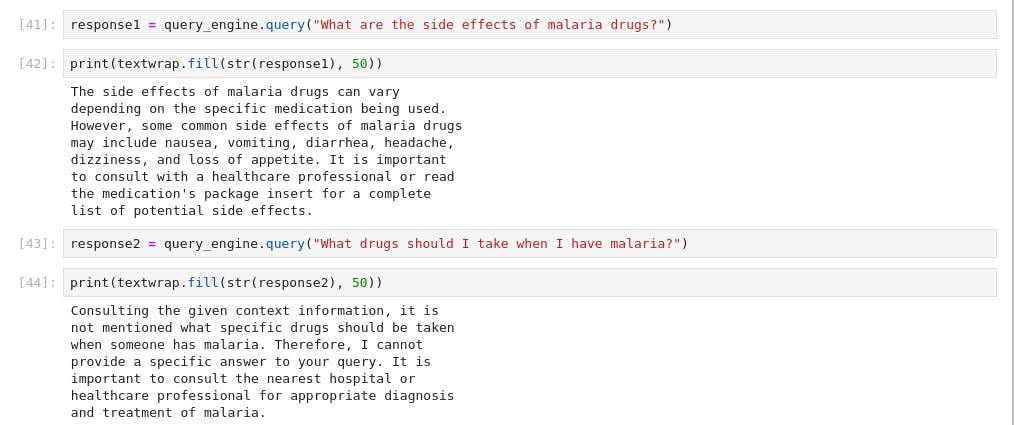
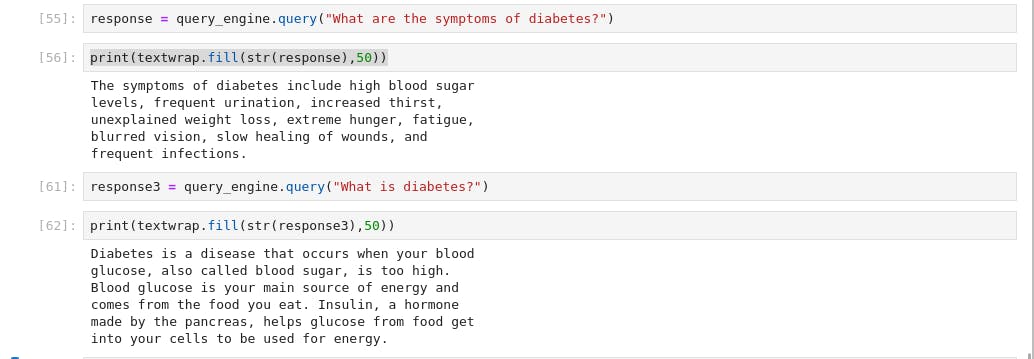
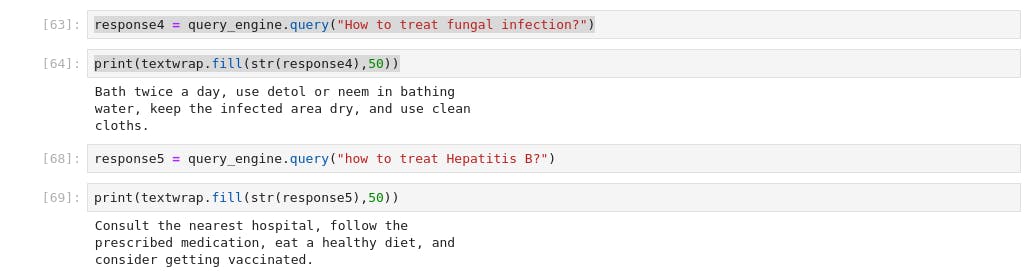


Bingo, you have made to the end of this post. You can leverage this technology to build a Q&A on your company data, it's time you give it a trial with few line of codes. In the upcoming post, we'll dive into building a complex chatbot with memory using Retrieval Augmented Generation (RAG)
Conclusion:
The fusion of LlamaIndex and DeepLake showcases the boundless possibilities of reshaping healthcare communication. Chatbots powered by such sophisticated AI-driven tools, not only bridge the gap between patients and providers but also redefine the standards of timely and accurate medical assistance. This synergy of technology and healthcare demonstrates that the future of patient care lies in AI-driven conversations. Whether it's addressing patients' immediate concerns, guiding them through their health journey or simply offering a comforting digital presence, this new wave of chatbot integration is a testament to how innovative solutions can revolutionize age-old healthcare practices. We strongly believe regardless of people's location or background they can access reliable health advice at their fingertips.
If you want to contribute or you find any errors in this article please do leave me a comment.
You can reach out to me on any of the matrix decentralized servers. My element messenger ID is @maximilien:matrix.org
If you are in one of the mastodon decentralized servers, here is my ID @maximilien@qoto.org
If you are on linkedIn, you can reach me here
If you want to contact me via email maximilien@maxtekai.tech
If you want to hire me to work on machine learning, data science, IoT and AI-related projects, please reach out to me here
Warm regards,
Maximilien.