Large Language Models: A Dive Into Three Distinct Architectures
The Three Pillars of Language Processing: Understanding MLM, CLM, and Seq2Seq


Introduction
The rise of large language models has changed the landscape of Natural Language Processing (NLP) dramatically. Their ability to comprehend, generate, and interact using human language has unlocked numerous applications, from chatbots to content creation. In this post, we'll journey through three foundational architectures powering these behemoths: Masked Language Models, Causal Language Models, and Sequence-to-Sequence Language Models.
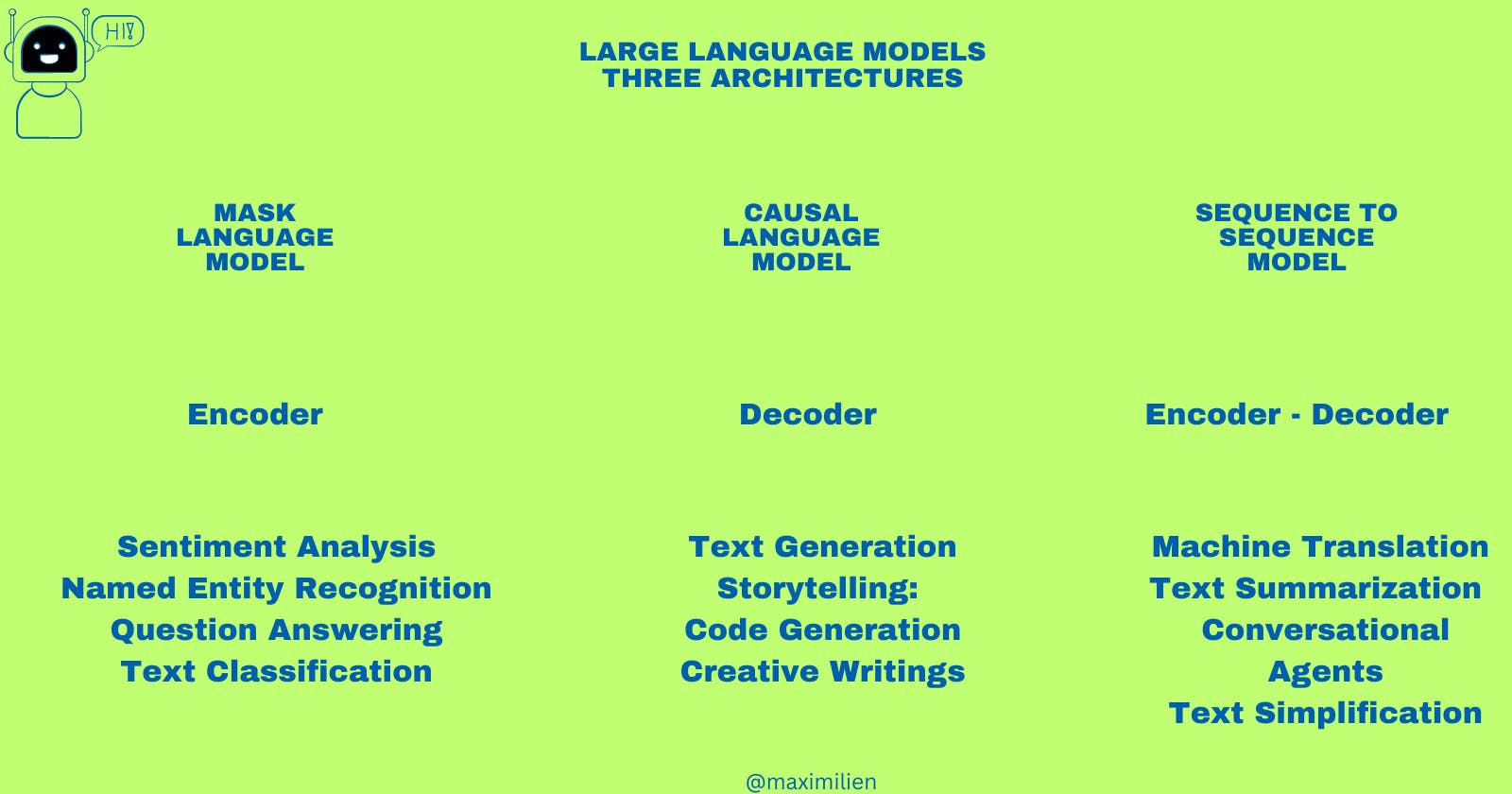
1. Masked Language Model (MLM) - Encoding the Unknown
Architecture:
MLM is designed to predict a missing word in a sentence. During training, random words in a sentence are replaced with a '[MASK]' token, and the model learns to predict these masked words.
Example:
Sentence: "I love [MASK] ice cream."
Prediction: "chocolate"
Prominent models
BERT (Bidirectional Encoder Representations from Transformers): Developed by Google, BERT revolutionized many NLP tasks by pre-training on large amounts of text and then fine-tuning on specific tasks.
RoBERTa (A Robustly Optimized BERT Pretraining Approach): A variation of BERT, RoBERTa tweaks the training process and methodology to achieve even better performance.
DistilBERT: A distilled version of BERT, it maintains most of the performance while being faster and smaller.
ALBERT (A Lite BERT): It reduces the number of parameters in BERT without a significant drop in performance.
Applications:
Sentiment Analysis: Determining if a review is positive or negative using models like BERT.
Named Entity Recognition: Identifying entities such as names, places, and organizations in a sentence with models like DistilBERT.
Question Answering: Extracting specific answers from large texts, as seen with models like RoBERTa on the SQuAD dataset.e
Text Classification: Categorizing text into predefined groups using models like ALBERT.
2. Causal Language Model (CLM) - Decoding the Sequence
Architecture:
CLMs, or autoregressive models, generate text by predicting the next word in a sequence based on the previous words. They're "causal" because the prediction at time 't' is only affected by words from time 't-1' and before.
Example:
Seed: "Once upon a time,"
Generated continuation: "... in a land far away, there was a brave knight."
Prominent models
GPT (Generative Pre-trained Transformer): OpenAI's model that is pre-trained on large corpora and can generate coherent paragraphs of text. Its iterations include GPT-2 and the more recent GPT-3.
CTRL (Conditional Transformer Language Model): Developed by Salesforce, CTRL can generate content conditioned on control codes, allowing for more specific text generation.
XLNet: It combines the strengths of both BERT and GPT by predicting words in a dynamic order.
Applications:
Text Generation: Producing coherent paragraphs of text or completing prompts using GPT series.
Storytelling: Given a starting point, generating a story or narrative as seen with models like CTRL.
Code Generation: Producing programming code based on prompts, often explored using GPT models.
Creative Writing: Assisting writers in generating poems, song lyrics, and more.
3. Sequence-to-Sequence (Seq2Seq) Model - Encoding to Decoding
Architecture:
Seq2Seq models consist of two main parts: an encoder and a decoder. The encoder processes the input sequence and compresses the information into a 'context vector'. The decoder then uses this vector to produce the output sequence.
Example:
Input (Encoder): "Bonjour"
Output (Decoder): "Hello"
Prominent models
T5 (Text-to-Text Transfer Transformer): Introduced by Google, T5 treats every NLP problem as a text-to-text problem, making it highly versatile.
BART (Bidirectional and Auto-Regressive Transformers): Introduced by Facebook AI, BART is trained to auto-encode (with some noise in the text) and has achieved strong performance in tasks like summarization.
MarianMT: A state-of-the-art Seq2Seq model specifically designed for neural machine translation.
TransformerXL: While not strictly a Seq2Seq model, TransformerXL introduced mechanisms to remember longer sequences, making it relevant for tasks that benefit from understanding over extended contexts
Applications:
Machine Translation: Translating a sentence from one language to another, as done by MarianMT.
* Text Summarization: Shortening a lengthy article into a concise summary, a strong suit of BART.
* Conversational Agents: Building chatbots that can have back-and-forth interactions using models like T5.
* Text Simplification: Converting complex sentences into simpler versions for better understanding.
Conclusion
The diverse architectures of large language models showcase the breadth and depth of possibilities in NLP. From filling in the gaps with MLMs, spinning tales with CLMs, or translating and summarizing with Seq2Seq, these models have transformed the way machines understand and generate human language. As we continue to push the boundaries of NLP, it's exciting to envision where these foundational architectures will take us next.